Как себе поставить голос: Как поставить голос для пения
Ставим голос / Хабр
Безусловно, в настоящее время коммуникативные навыки играют ключевую роль в жизни человека. От них во многом зависит успех в жизни, они влияют на отношение к тебе других людей. Данная статья посвящена голосу.Согласитесь, обладание хорошим голосом очень важное и полезное свойство человека. Голос мы используем чаще мыла, еды и женщин. Он заполняет всю нашу жизнь, он используется всегда и везде. Голос является одним из важнейших средств взаимодействия. Но голос — не совершенен, он имеет свойство портиться. Но в отличие от сгоревших пельменей его вполне можно восстановить, и улучшить. Данная статья является введением в эту тему, и помимо теории, вы найдете тут практические упражнения.
Бла бла бла
По постановке голоса существует как множество учебников, так и огромное количество курсов на основе этих учебников. Если вас заинтересует эта тема, то рекомендую пройти специальные курсы, где обученный человек будет более кропотливо вас учить, что возымеет больший эффект.
Данная же статья, хотя не является профессиональным пособием, вполне удовлетворит любовь многих людей через интернет
Хочу написать цикл статей если тема будет востребована, посему ваши отзывы будут нужны.
Данная глава про…
Ваш громкий, всеобъемлющий и разрушающий голос
Наверняка вы встречали людей, которые говорят громко, их голос заполняет все помещение, сковывает движение и вызывает уважение(каламбур).А так же часто вы видели людей которые бурчат себе под нос, которых приходиться переспрашивать что они сказали, которые голосом ставят себя ниже собеседника.
 Ясен день, лучше стремиться к первому описанному типу.
Ясен день, лучше стремиться к первому описанному типу.От природы каждый человек имеет громкий голос. Сейчас вспоминаем как орут дети на улице когда играют, как все затыкают уши, когда детишки плачут. Убедил.
Но с возрастом в виду ряда причин это прекрасное свойство покидает нас. Человек с испорченным жизнью голосом может перекричать ребенка, но только из-за больших легких, и натренированных мышц, которые усилят звук. Но по времени ребенка не сможет уделать. И болеть перенапрягшиеся мышцы будут. Все дело в том, что воздух из легких у ребенка идет без сопротивления, нежели у взрослого человека.
Аналогия:
Вы поставили в квартире новый кран. Вода ровно течет, все круто. Но со временем фильтр может забиться, и вода уже будет стекать не идеально гладко, а, как например у меня, с одной стороны.
В теле человека же со временем такая вещь как диафрагма начинает барахлить. У ребенка она не блокирует выход воздуха, поэтому звук получается чистый и сильный.
В поисках диафрагмы
Положите руку на то место, где начинают расходиться ребра, так чтобы часть ладони лежала на ребрах, часть — на мягком пузечке (еще известно как солнечное сплетение).Ну вот, вы слишком быстро все нашли, и этот пункт можно было бы закончить. Но ведь мы хотим узнать еще некоторых ценных вещей о диафрагме, неправда ли?
Солнечное сплетение, подДЫХ. Вспоминаете? Удары в эту часть болезненны, и главное сбивают дыхание. Что-то вспоминается, отлично. Мы уже подобрались близко.
Положите руку обратно, и протяните звук «Р-р-рр». Вибрации которые вы чувствуете происходят в диафрагме. Теперь мы точно знаем что нашли ее.
Если вы смотрели когда-нибудь фильмы со всякими каратистами, или даже сами занимались борьбой близкой к востоку, то вы сталкивались с таким ритуалом, когда спортсмен стоит выпрямив спину, потом прижимает руки к себе и при этом поджимая живот, очень громко орет.
 Повторяю что фильмы немецкие, а с каратистами.
Повторяю что фильмы немецкие, а с каратистами.Если вы не занимались до этого своим голосом, то на 90% можно быть уверенным, что пока вы читали до этого момента, вы животом при вдохе и выходе не работали.
Из вышеизложенного нам стало понятно, что диафрагма влияет на силу нашего голоса. Теперь осталось ее заставить работать на нас.
Практика
Не разбегайтесь. Еще немного теории. В силу, опять таки, жизненных причин наш голос напряжен. Его надо расслабить. Когда вы расслаблены — то голос льется, как реченька журчит.Крайне приятная вещь, которую хоть раз в жизни ощущал каждый человек — зевота.
Она доставляет нам удовольствие, не хуже немецкого кина, но в процессе она действует на расслабление. Попробуйте зевните.
Предупреждение: если с вами рядом кто-то находиться, то есть вероятность цепной реакции. Вот кстати способ доставить удовольствие беспроводным способом.
Вот кстати способ доставить удовольствие беспроводным способом.
Ну как, зевнули? Зевнуть надо так хорошо, как вы зеваете перед тем как удовлетворенно выключить будильник и проспать все на свете.
Возможно не получилось зевнуть хорошо. Наверно зевнулось «так себе, у меня бывало и лучше». Чтобы зевнуть так, чтобы гордость взяла, выполните следующий действия.
Но зевок — это не самое важное.

Не смотря на то, что уши при зевке закладывает — вы почувствовали каким громким был ваш голос.
Позевайте побольше, потом попробуйте произнести какую-нибудь фразу.
Вы сразу заметите, что ваш голос изменился, стал громче. По-умному — вы резонируете ваш голос, и за счет этого получается громче. Таким голос должен быть всегда.
Итоги
Громкий голос достаточно быстро пройдет, поэтому не расстраивайтесь.Главное — сейчас вы осознали силу своего голоса, и поняли нужно ли вам это.
Есть специальные упражнения по закреплению такого уровня, но эта не есть цель статьи, цель статьи было попробовать что это такое.
А на этом статья завершается, спасибо что были с нами, буду рад если вы извлекли что-то новое для себя, и главное полезное.
Как поставить голос самостоятельно
Красивый мелодичный голос – настоящий подарок судьбы, позволяющий его обладателю с легкостью завладевать вниманием собеседника или придавать своим словам особую значимость и глубину. Однако, даже если от природы вы не были награждены этим драгоценным даром, мы расскажем вам, как поставить голос самостоятельно, тренируя голосовые связки, как и любую другую группу мышц.
Прежде чем приступить к регулярным занятиям, следует определиться, какому именно голосовому аспекту следует уделить особое внимание. Одних исполнителей не устраивает сила голоса, других – чистота, третьим хотелось бы изменить неприятный тембр. В зависимости от проблемы следует выбирать и спектр специальных упражнений. Впрочем, большинство начинающих певцов не вникают в профессиональные термины, желая просто добавить собственному исполнению силы, уверенности и чистоты звучания.
Дышите — не дышите
Правильное дыхание – основа основ любой певческой методики. От этого напрямую зависит сила и выразительность голоса, ведь научившись петь за счет правильного управления диафрагмой, а не напряжения голосовых связок, вы впоследствии убережете себя от травм гортани и значительно повысите качество исполнения.
От этого напрямую зависит сила и выразительность голоса, ведь научившись петь за счет правильного управления диафрагмой, а не напряжения голосовых связок, вы впоследствии убережете себя от травм гортани и значительно повысите качество исполнения.
Существует целый ряд специальных упражнений, призванных научить человека правильно и ритмично дышать. Большинство из них вполне можно выполнять самостоятельно, без контроля специалиста:
- «Легкое дуновение». Для выполнения упражнения вам понадобиться легкое птичье перышко небольшого размера. Постоянно варьируя силу выдоха, попытайтесь заставить легкие пушинки трепетать только по краям, а потом добиться их общего движения.
- «Гласный ряд». Остановившись перед зеркалом, примите правильное положение и постарайтесь пропеть гласный ряд. Первым идет звук «и», который нужно произносить на выдохе. Следующим идет «э», потом «а», «о» и «у» завершает распевку. Выполняя такое упражнение каждый день, ни в коем случае не меняйте порядок пения.

- «Воздушный змей». Постарайтесь удерживать на весу в воздухе подброшенный вверх полиэтиленовый пакет, имитируя движения воздушных масс, играющих легким змеем.

Чистота – залог успеха
Вопреки мнению большинства дилетантов, чистота голоса имеет куда большее значение, чем сила звука. Выполняя любые упражнения, будь то декламация или пение, старайтесь произносить слова четко и чисто, никуда не торопясь. Такое усердие уже само по себе является отличной практикой постановки голоса. Кроме этого преподаватели предлагают практические занятия, призванные избавить звучание от всевозможных помех:
- Классические певческие распевки, во время которых певец подхватывает звучащую на инструменте ноту, считаются лучшим упражнением для постановки голоса. Чаще всего в качестве аккомпанемента используется фортепиано, однако звучание гитарной струны с голосовым сопровождением позволяет добиться требуемой чистоты ничуть не хуже.
- «Зевок». Вы когда-нибудь пытались зевнуть, оставляя рот закрытым? Попытайтесь воспроизвести это действие, добившись максимального открытия неба. Запомнив ощущение, постарайтесь, не раскрывая рта, негромко пропеть несколько простых нот: до-ре-ми или ре-ми-до. Звук, исходящий из вашего рта, должен напоминать тихую и нежную колыбельную – не нужно ни кричать, ни напрягать связки.

Твой голос – твоя сила
После тяжелой работы по совершенствованию чистоты голоса, самое время заняться тренировкой сильного звучания. Здесь главное неторопливость и последовательность. Чрезмерное напряжение связок может привести к травмам и, как следствие, необратимым процессам в голосовой системе человека. Вот несколько упражнений, помогающих победить слабость тембра:
- «Тарзан». Помните, как легендарный человек-обезьяна оповещал лес о своем присутствии? Правильно, он воспроизводил громкие устрашающие звуки, стуча кулаками по груди. Попробуйте повторить этот зрелищный голливудский трюк. Только кричать нужно не что попало, а определенный набор гласных, звучащих, примерно, как и-э-а-о-у. Выкрикивая их на выдохе, ударяйте кулаком себе по диафрагме. Главное – кричать как можно громче и стучать не очень сильно, чтобы обойтись без синяков.
- Постарайтесь извлекать звуки не только непосредственно горлом и речевым аппаратом, но и всем своим телом. Так вы добавите голосу не только силу, но и необходимую бархатистость и глубину.
- Почаще подпевайте проигрывателю с фонограммами известных исполнителей. Это несложное упражнение может частично заменить занятия с квалифицированным преподавателем, профессионально ставящим голос.
 Попробуйте повторить этот зрелищный голливудский трюк. Только кричать нужно не что попало, а определенный набор гласных, звучащих, примерно, как и-э-а-о-у. Выкрикивая их на выдохе, ударяйте кулаком себе по диафрагме. Главное – кричать как можно громче и стучать не очень сильно, чтобы обойтись без синяков.
Попробуйте повторить этот зрелищный голливудский трюк. Только кричать нужно не что попало, а определенный набор гласных, звучащих, примерно, как и-э-а-о-у. Выкрикивая их на выдохе, ударяйте кулаком себе по диафрагме. Главное – кричать как можно громче и стучать не очень сильно, чтобы обойтись без синяков.Ну и напоследок несколько советов, касающихся осанки певца или декламатора:
- Привычка держать спину ровно, не меньше регулярных занятий, помогает добиться сильного и чистого звучания голоса.
- Если пение не сопровождается вашим собственным аккомпанементом, лучше не петь сидя – так вы сминаете диафрагму, не позволяя обеспечить нормальную циркуляцию воздуха.
- Если присесть все-таки пришлось, обеспечьте ногам хорошую устойчивую опору. Поджимание одной ноги или закидывание конечностей друг на друга вредит качеству исполнения.

Предыдущая статьяЧто нравится мужчинам в постели?
Следующая статьяЧем мазать ветрянку?
ЕЩЁ БОЛЬШЕ НОВОСТЕЙ
Могу ли я создать ИИ-голос самого себя? 🚀 Speechify
С появлением искусственного интеллекта идея создания собственного цифрового голоса с помощью ИИ стала реальностью. Это может показаться пугающим, но использовать технологию озвучивания ИИ для создания уникального цифрового представления о себе на удивление просто. В этой статье мы рассмотрим возможности голосовой технологии ИИ, популярные платформы и доступные инструменты, а также способы создания собственного голоса ИИ. Мы также рассмотрим этические соображения и потенциальное неправомерное использование голосовой технологии ИИ.
Мы также рассмотрим этические соображения и потенциальное неправомерное использование голосовой технологии ИИ.
Прежде чем углубиться, давайте подробнее рассмотрим, что такое голосовая технология ИИ. Технология голосового ИИ включает в себя создание синтетического голоса, похожего на человеческий. Его можно использовать для многих целей, таких как демонстрации продуктов, аудиокниги и даже виртуальные помощники. Но одно из самых захватывающих применений голосовой технологии ИИ — это создание цифровой версии вашего собственного голоса.
Голосовая технология искусственного интеллекта прошла долгий путь с момента своего появления. В первые дни голоса, созданные ИИ, были роботизированными, и им не хватало естественного потока человеческой речи. Но благодаря достижениям в области машинного обучения и обработки естественного языка голосовая технология ИИ стала более сложной и теперь может воспроизводить образцы человеческой речи с поразительной точностью.
Синтез речи ИИ — это процесс создания синтетического голоса с использованием алгоритмов ИИ. Он включает в себя обучение модели машинного обучения на большом количестве голосовых записей, что позволяет ей изучать нюансы речи и интонации. После того, как модель обучена, она может генерировать текст в речь естественным голосом.
Одним из ключевых преимуществ синтеза голоса ИИ является его способность генерировать речь на нескольких языках и с разными акцентами. Это делает его бесценным инструментом для предприятий, работающих на мировых рынках, и для людей, которые хотят общаться с людьми из разных уголков мира.
Как работает генерация голоса ИИ Генерация голоса ИИ включает в себя ввод введенного текста и преобразование его в голосовой вывод. Входной текст анализируется моделью ИИ, которая определяет подходящий голос и интонацию для использования при создании вывода. Сгенерированный вывод можно дополнительно настроить, отрегулировав высоту тона, скорость и другие атрибуты голоса.
Генерация голоса ИИ не ограничивается только приложениями TTS. Его также можно использовать для клонирования голоса ИИ, когда голос человека воспроизводится с использованием технологии ИИ. У этого есть много потенциальных применений, таких как создание персонализированных голосовых помощников или предоставление людям возможности общаться с близкими, которые скончались.
В заключение следует сказать, что голосовая технология искусственного интеллекта произвела революцию в нашем взаимодействии с машинами и открыла новые возможности для общения и развлечений. Поскольку технология продолжает развиваться, мы можем ожидать появления еще более интересных приложений в будущем.
Популярные голосовые платформы и инструменты ИИ Существует несколько популярных инструментов и платформ ИИ, которые упрощают создание собственного голоса для ваших аудиофайлов. Эти инструменты революционизируют то, как мы взаимодействуем с технологиями, и открывают новые возможности для компаний, создателей контента и частных лиц.
В этом разделе мы более подробно рассмотрим некоторые из самых популярных голосовых платформ и инструментов ИИ, а также рассмотрим их функции и возможности. И вам не нужно беспокоиться о ценах на эти платформы, поскольку большинство из них доступны по цене и даже предоставляют бесплатные планы, которые вы можете использовать перед обновлением.
API преобразования текста в речь GoogleAPI преобразования текста в речь Google предоставляет простой и удобный интерфейс для создания высококачественного речевого вывода. Он доступен на нескольких языках и может быть настроен с помощью ряда голосовых атрибутов. Эта платформа хорошо подходит для широкого спектра приложений, от голосовых приложений до вспомогательных технологий для людей с ограниченными возможностями.
API преобразования текста в речь Google использует алгоритмы машинного обучения для создания естественно звучащей речи, отличающейся высокой точностью и отзывчивостью. Его можно интегрировать в различные устройства и приложения, включая смартфоны, умные колонки и устройства умного дома.
Amazon Polly — еще одна популярная голосовая платформа с искусственным интеллектом, которая предлагает широкий спектр голосовых опций и функций настройки. Сгенерированные им голоса хорошо подходят для использования как в коммерческих, так и в личных проектах. Эта платформа использует алгоритмы глубокого обучения для создания очень реалистичного речевого вывода, неотличимого от человеческой речи.
Amazon Polly предлагает различные варианты голоса, включая мужские и женские голоса на нескольких языках. Он также позволяет пользователям настраивать высоту тона, скорость и громкость генерируемой речи, что делает его очень гибкой платформой для широкого спектра приложений.
Преобразование текста в речь IBM Watson Преобразование текста в речь IBM Watson — это облачная платформа искусственного интеллекта, обеспечивающая высокоточный и быстрый преобразование текста в речь. Он предлагает как стандартные, так и нейронные варианты голоса и может быть дополнительно настроен с помощью ряда голосовых атрибутов. Эта платформа хорошо подходит для использования в голосовых приложениях, виртуальных помощниках и чат-ботах.
Эта платформа хорошо подходит для использования в голосовых приложениях, виртуальных помощниках и чат-ботах.
IBM Watson Text to Speech использует алгоритмы глубокого обучения для создания очень реалистичного вывода речи, неотличимого от человеческой речи. Он также предлагает ряд параметров настройки, в том числе возможность регулировать скорость речи, высоту тона и громкость сгенерированной речи.
OpenAI GPT-3OpenAI GPT-3 — передовая платформа искусственного интеллекта, способная воспроизводить очень реалистичную речь. Он имеет различные варианты использования и широкий спектр приложений, от чат-ботов до виртуальных помощников, и предлагает множество вариантов настройки. Эта платформа хорошо подходит для предприятий и частных лиц, которым требуется очень реалистичный и отзывчивый речевой вывод.
OpenAI GPT-3 использует самые современные алгоритмы обработки естественного языка для создания очень реалистичного речевого вывода, неотличимого от человеческой речи. Он также предлагает ряд параметров настройки, в том числе возможность регулировать скорость речи, высоту тона и громкость сгенерированной речи.
Он также предлагает ряд параметров настройки, в том числе возможность регулировать скорость речи, высоту тона и громкость сгенерированной речи.
Помимо этих опций, вы можете попробовать Play.ht, Microsoft Azure и даже Murf.ai для преобразования текста в речь для транскрипции, редактирования видео и изменения голоса в реальном времени. В целом, эти голосовые платформы и инструменты ИИ меняют наше взаимодействие с технологиями и открывают новые возможности как для бизнеса, так и для частных лиц.
Независимо от того, создаете ли вы голосовое приложение или виртуального помощника, эти платформы предлагают гибкость и возможности настройки, необходимые для создания действительно уникального и увлекательного взаимодействия с пользователем. А с помощью нескольких руководств вы сможете создавать реалистичные компьютерные голоса для своих проектов.
Создание собственного голоса ИИ Если вы хотите создать свой собственный цифровой, но реалистичный голос, будь то для подкастов, TikTok, видео на YouTube или социальных сетей, вам необходимо предпринять несколько важных шагов. Создание собственного голоса ИИ может быть увлекательным и полезным занятием, но оно требует определенных технических знаний и оборудования. Вот более подробный взгляд на этапы:
Создание собственного голоса ИИ может быть увлекательным и полезным занятием, но оно требует определенных технических знаний и оборудования. Вот более подробный взгляд на этапы:
Первым шагом в создании собственного голоса ИИ является запись высококачественных образцов собственного голоса. Это важно, потому что модель ИИ, которую вы обучаете, будет основана на этих образцах. Вам понадобится высококачественный микрофон и программное обеспечение для записи, чтобы точно записать ваш голос.
При записи образцов голоса важно говорить четко и естественно. Вы должны записать различные фразы и предложения, чтобы убедиться, что модель научилась генерировать естественно звучащую речь в различных контекстах. Также рекомендуется записывать свой голос в разных условиях, чтобы зафиксировать разные акустические характеристики.
Обучение модели ИИ Когда у вас есть образцы голоса, вам нужно обучить модель ИИ.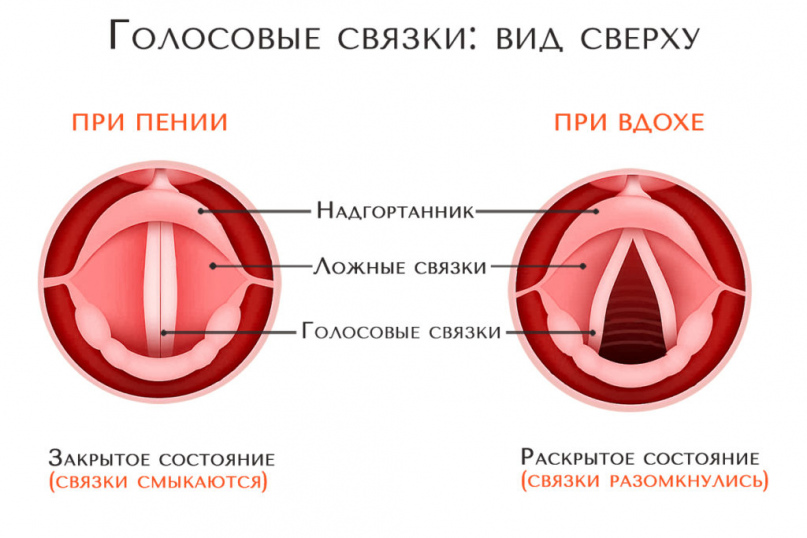 Это включает в себя использование такой платформы, как Google Text-to-Speech или Amazon Polly, для обучения модели с помощью образцов вашего голоса. Эти платформы используют алгоритмы машинного обучения для создания цифрового голоса, похожего на ваш.
Это включает в себя использование такой платформы, как Google Text-to-Speech или Amazon Polly, для обучения модели с помощью образцов вашего голоса. Эти платформы используют алгоритмы машинного обучения для создания цифрового голоса, похожего на ваш.
Обучение модели ИИ может занять некоторое время, в зависимости от сложности модели и объема используемых данных. Важно набраться терпения и предоставить модели как можно больше данных, чтобы она точно запомнила ваш голос.
Тонкая настройка голоса ИИПосле обучения модели вам необходимо настроить голос, чтобы он звучал естественно и соответствовал вашим предпочтениям. Это включает в себя настройку таких атрибутов, как высота звука, скорость и тон, для создания уникального цифрового голоса, звучащего как вы.
При точной настройке голоса ИИ важно внимательно слушать вывод и при необходимости вносить коррективы. Возможно, вам придется несколько раз настроить параметры модели, прежде чем вы добьетесь желаемого результата.
Создание собственного голоса ИИ может быть интересным и полезным занятием, но оно требует определенных технических знаний и оборудования. С правильными инструментами и небольшим терпением вы можете создать цифровой голос, который будет звучать так же, как вы.
Этические соображения и потенциальное неправомерное использованиеНесмотря на то, что голосовая технология ИИ имеет множество интересных применений, необходимо также учитывать некоторые этические соображения и возможность неправомерного использования.
По мере того, как голосовая технология ИИ продолжает развиваться, становится все проще создавать цифровые голоса, которые звучат почти неотличимо от настоящих человеческих голосов. Эта технология может революционизировать способ нашего общения, но она также поднимает некоторые важные этические вопросы.
Проблемы с конфиденциальностью Одной из потенциальных проблем является проблема с конфиденциальностью. Если ваш цифровой голос создается без вашего ведома или согласия, он может быть использован в злонамеренных целях, таких как выдача себя за другое лицо или мошенничество. Например, кто-то может использовать ваш голос, чтобы сделать мошеннический телефонный звонок или создать фальшивую аудиозапись, из-за которой создается впечатление, что вы сказали что-то, чего не говорили.
Если ваш цифровой голос создается без вашего ведома или согласия, он может быть использован в злонамеренных целях, таких как выдача себя за другое лицо или мошенничество. Например, кто-то может использовать ваш голос, чтобы сделать мошеннический телефонный звонок или создать фальшивую аудиозапись, из-за которой создается впечатление, что вы сказали что-то, чего не говорили.
Есть также опасения по поводу того, как эти цифровые голоса могут быть использованы для наблюдения. Если кто-то сможет создать ваш цифровой голос, он потенциально может использовать его, чтобы выдать себя за вас и получить доступ к конфиденциальной информации.
Дипфейковые голоса и дезинформация Другая проблема связана с возможностью дипфейковых голосов и дезинформации. Их можно использовать для манипулирования и обмана людей, что в конечном итоге приводит к пагубным последствиям. Например, дипфейк-голос может использоваться для распространения ложной информации о политическом кандидате или для манипулирования фондовым рынком.
По мере того, как голосовая технология ИИ продолжает совершенствоваться, становится все проще создавать убедительные поддельные голоса. Это означает, что как никогда важно проявлять бдительность в отношении информации, которую мы потребляем, и осознавать возможность обмана.
Юридические последствияТакже могут быть юридические последствия создания собственного цифрового голоса. Например, если голос используется для создания контента без вашего разрешения, могут возникнуть проблемы с авторскими правами или интеллектуальной собственностью. Кроме того, если кто-то использует ваш цифровой голос для совершения преступления, вы можете быть привлечены к ответственности.
Перед созданием собственного цифрового голоса важно проконсультироваться с юристом, чтобы убедиться, что вы осведомлены о любых возможных юридических проблемах.
Создавайте естественно звучащие голоса с помощью простой в использовании платформы искусственного интеллекта Speechify Платформа искусственного интеллекта Speechify предлагает революционный подход к созданию естественно звучащих голосов. Сочетая передовые технологии с интуитивно понятным интерфейсом, Speechify позволяет пользователям легко создавать различные голоса, которые звучат так, как будто они были записаны настоящими актерами.
Сочетая передовые технологии с интуитивно понятным интерфейсом, Speechify позволяет пользователям легко создавать различные голоса, которые звучат так, как будто они были записаны настоящими актерами.
Что отличает Speechify от других, так это его способность адаптироваться к различным акцентам и стилям речи, что обеспечивает более персонализированный опыт прослушивания. Если вам нужно создать аудиоклип для видеопрезентации или создать естественно звучащий диалог для чат-бота, Speechify — это лучший инструмент, который поможет вам достичь ваших целей.
В общем, создать лучший голос ИИ для себя — выполнимая, но сложная задача. Использование передовых технологий, таких как openAI GPT-3 и приложение для преобразования текста в речь Speechify, может помочь вам приблизиться к реальности. Может показаться заманчивым прыгнуть в него с головой, но все же следует соблюдать осторожность при работе с конфиденциальными данными или алгоритмами, поэтому вместо этого попробуйте Speechify для себя!
Обучение собственной модели голоса — Служба распознавания речи — Службы искусственного интеллекта Azure
- Статья
В этой статье вы узнаете, как обучить собственный нейронный голос с помощью портала Speech Studio.
Важно
Обучение пользовательскому нейронному голосу в настоящее время доступно только в некоторых регионах. После обучения модели голоса в поддерживаемом регионе вы можете при необходимости скопировать ее в ресурс «Речь» в другом регионе. См. сноски в таблице регионов для получения дополнительной информации.
Продолжительность обучения зависит от объема обучаемых данных. В среднем для обучения пользовательского нейронного голоса требуется около 40 вычислительных часов. Пользователи стандартной подписки (S0) могут тренировать четыре голоса одновременно. Если вы достигли предела, подождите, пока хотя бы одна из ваших голосовых моделей не закончит обучение, а затем повторите попытку.
Примечание
Несмотря на то, что общее количество часов, необходимых для каждого метода обучения, может варьироваться, для каждого метода применяется одинаковая цена за единицу. Для получения дополнительной информации см. сведения о ценах на обучение Custom Neural.
Для получения дополнительной информации см. сведения о ценах на обучение Custom Neural.
Выберите метод обучения
После проверки ваших файлов данных вы можете использовать их для создания собственной модели нейронного голоса. Когда вы создаете собственный нейронный голос, вы можете выбрать для его обучения один из следующих методов:
Нейронный: создайте голос на том же языке, что и ваши обучающие данные, выберите метод Нейронный .
Нейронный — межъязыковой: создайте дополнительный язык для вашей модели голоса, чтобы говорить на языке, отличном от вашего обучающего данных. Например, с
zh-CNобучающие данные, вы можете создать голос, который говоритen-US. Язык обучающих данных и целевой язык должны быть одним из языков, поддерживаемых для межъязыкового голосового обучения. Вам не нужно готовить обучающие данные на целевом языке, но ваш тестовый сценарий должен быть на целевом языке.Нейронный — мультистиль: создайте собственный нейронный голос, который говорит в разных стилях и с разными эмоциями, без добавления новых обучающих данных.
Мультистиль голоса особенно полезны для персонажей видеоигр, диалоговых чат-ботов, аудиокниг, читателей контента и многого другого. Чтобы создать многостильный голос, вам просто нужно подготовить набор общих обучающих данных (не менее 300 высказываний) и выбрать один или несколько из предустановленных целевых стилей речи. Вы также можете создать несколько пользовательских стилей, предоставив образцы стилей (не менее 100 высказываний на стиль) в качестве дополнительных обучающих данных для одного и того же голоса. Поддерживаемые предустановленные стили различаются в зависимости от языка. См. список предустановленных стилей для разных языков.
 Мультистиль голоса особенно полезны для персонажей видеоигр, диалоговых чат-ботов, аудиокниг, читателей контента и многого другого. Чтобы создать многостильный голос, вам просто нужно подготовить набор общих обучающих данных (не менее 300 высказываний) и выбрать один или несколько из предустановленных целевых стилей речи. Вы также можете создать несколько пользовательских стилей, предоставив образцы стилей (не менее 100 высказываний на стиль) в качестве дополнительных обучающих данных для одного и того же голоса. Поддерживаемые предустановленные стили различаются в зависимости от языка. См. список предустановленных стилей для разных языков.
Мультистиль голоса особенно полезны для персонажей видеоигр, диалоговых чат-ботов, аудиокниг, читателей контента и многого другого. Чтобы создать многостильный голос, вам просто нужно подготовить набор общих обучающих данных (не менее 300 высказываний) и выбрать один или несколько из предустановленных целевых стилей речи. Вы также можете создать несколько пользовательских стилей, предоставив образцы стилей (не менее 100 высказываний на стиль) в качестве дополнительных обучающих данных для одного и того же голоса. Поддерживаемые предустановленные стили различаются в зависимости от языка. См. список предустановленных стилей для разных языков.Язык обучающих данных должен быть одним из языков, поддерживаемых для пользовательского нейронного голосового нейронного, межъязыкового или мультистилевого обучения.
Тренировка модели пользовательского нейронного голоса
Чтобы создать собственный нейронный голос в Speech Studio, выполните следующие действия для одного из следующих методов:
- Нейронный
- Нейронный — межъязыковой
- Нейронный — мультистиль
- Войдите в Speech Studio.
- Выберите Пользовательский голос > Название вашего проекта > Обучить модель > Обучить новую модель .
- Выберите Neural в качестве метода обучения для вашей модели, а затем выберите Next . Чтобы использовать другой метод обучения, см. Нейронный — кросс-лингвальный или Нейронный — мультистиль.
- Выберите версию рецепта обучения для вашей модели. По умолчанию выбирается последняя версия. Поддерживаемые функции и время обучения могут различаться в зависимости от версии. Обычно для достижения наилучших результатов рекомендуется последняя версия. В некоторых случаях вы можете выбрать более старую версию, чтобы сократить время обучения.
- Выберите данные, которые вы хотите использовать для обучения. Дублирующиеся названия аудио будут удалены из обучения. Убедитесь, что выбранные вами данные не содержат одинаковых имен аудио в нескольких ZIP-файлах. Для обучения могут быть выбраны только успешно обработанные наборы данных. Проверьте статус обработки данных, если вы не видите свою тренировочную выборку в списке.
- Выберите файл диктора с заявлением о голосовом таланте, который соответствует диктору в ваших данных обучения.
- Выберите Далее .
- При каждом обучении автоматически создается 100 образцов аудиофайлов, чтобы помочь вам протестировать модель с помощью сценария по умолчанию. При желании вы также можете установить флажок рядом с Добавить мой собственный тестовый сценарий и предоставить свой собственный тестовый сценарий, содержащий до 100 высказываний, для тестирования модели без дополнительных затрат. Сгенерированные аудиофайлы представляют собой комбинацию автоматических тестовых сценариев и пользовательских тестовых сценариев. Дополнительные сведения см. в разделе Требования к тестовому сценарию.
- Введите Имя и Описание , чтобы помочь вам идентифицировать модель. Тщательно выбирайте имя. Название модели будет использоваться в качестве имени голоса в вашем запросе синтеза речи через вход SDK и SSML. Допускаются только буквы, цифры и несколько знаков препинания. Используйте разные имена для разных нейронных моделей голоса.
- При необходимости введите Описание , чтобы помочь вам идентифицировать модель. Обычно описание используется для записи имен данных, которые вы использовали для создания модели.
- Выбрать Далее .
- Проверьте настройки и установите флажок, чтобы принять условия использования.
- Выберите Отправить , чтобы начать обучение модели.

 Проверьте статус обработки данных, если вы не видите свою тренировочную выборку в списке.
Проверьте статус обработки данных, если вы не видите свою тренировочную выборку в списке. Название модели будет использоваться в качестве имени голоса в вашем запросе синтеза речи через вход SDK и SSML. Допускаются только буквы, цифры и несколько знаков препинания. Используйте разные имена для разных нейронных моделей голоса.
Название модели будет использоваться в качестве имени голоса в вашем запросе синтеза речи через вход SDK и SSML. Допускаются только буквы, цифры и несколько знаков препинания. Используйте разные имена для разных нейронных моделей голоса.В таблице Модель поезда отображается новая запись, соответствующая этой вновь созданной модели. Состояние отражает процесс преобразования ваших данных в голосовую модель, как описано в этой таблице:
| Состояние | Значение |
|---|---|
| Обработка | Ваша голосовая модель создается. |
| Успешно | Ваша голосовая модель создана и может быть развернута. |
| Ошибка | Ваша голосовая модель не прошла обучение. Причиной сбоя могут быть, например, невидимые проблемы с данными или проблемы с сетью. |
| Отменено | Тренировка для вашей голосовой модели отменена. |
Пока статус модели Обработка , вы можете выбрать Отменить тренировку , чтобы отменить вашу модель голоса. Плата за отмененное обучение не взимается.
После успешного завершения обучения модели вы можете просмотреть сведения о модели и протестировать ее.
Вы можете использовать инструмент создания аудиоконтента в Speech Studio для создания аудио и точной настройки развернутого голоса. Если применимо к вашему голосу, также можно выбрать один из нескольких стилей.
Переименуйте модель
Если вы хотите переименовать созданную вами модель, вы можете выбрать Клонировать модель , чтобы создать клон модели с новым именем в текущем проекте.
Введите новое имя в окне Clone voice model , затем выберите Submit . Текст «Neural» будет автоматически добавлен в качестве суффикса к названию вашей новой модели.
Проверка модели голоса
После того, как ваша модель голоса будет успешно построена, вы можете использовать сгенерированные образцы аудиофайлов для ее тестирования перед развертыванием для использования.
Качество голоса зависит от многих факторов, таких как:
- Размер обучающих данных.
- Качество записи.
- Точность файла стенограммы.
- Насколько хорошо записанный голос в обучающих данных соответствует характеру голоса, разработанного для предполагаемого варианта использования.
Выберите DefaultTests в разделе Testing , чтобы прослушать образцы аудио. Тестовые образцы по умолчанию включают 100 звуковых образцов, созданных автоматически во время обучения, чтобы помочь вам протестировать модель. В дополнение к этим 100 аудиозаписям, предоставляемым по умолчанию, к 9 также добавляются ваши собственные тестовые сценарии (максимум 100 высказываний), предоставляемые во время обучения.0005 DefaultTests установлено. Плата за тестирование с DefaultTests не взимается.
В дополнение к этим 100 аудиозаписям, предоставляемым по умолчанию, к 9 также добавляются ваши собственные тестовые сценарии (максимум 100 высказываний), предоставляемые во время обучения.0005 DefaultTests установлено. Плата за тестирование с DefaultTests не взимается.
Если вы хотите загрузить свои собственные тестовые сценарии для дальнейшего тестирования модели, выберите Добавить тестовые сценарии , чтобы загрузить свой собственный тестовый сценарий.
Перед загрузкой тестового сценария проверьте требования к тестовому сценарию. Плата за дополнительное тестирование с пакетным синтезом будет взиматься в зависимости от количества оплачиваемых символов. См. страницу с ценами.
В окне Добавить тестовые сценарии выберите Найдите файл , чтобы выбрать собственный сценарий, затем выберите Добавить , чтобы загрузить его.
Требования к тестовому сценарию
Тестовый сценарий должен представлять собой файл . txt размером менее 1 МБ. Поддерживаемые форматы кодирования включают ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE или UTF-16-BE.
txt размером менее 1 МБ. Поддерживаемые форматы кодирования включают ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE или UTF-16-BE.
В отличие от обучающих файлов расшифровки тестовый сценарий должен исключать идентификатор высказывания (имена файлов каждого высказывания). В противном случае эти идентификаторы произносятся.
Вот пример набора высказываний в одном файле .txt:
Это линия талии, и она падает. У нас проблемы со счетом. Это была Джанет Маслин.
Каждый абзац высказывания приводит к отдельному звуку. Если вы хотите объединить все предложения в одно аудио, сделайте их одним абзацем.
Примечание
Сгенерированные аудиофайлы представляют собой комбинацию сценариев автоматического тестирования и пользовательских сценариев тестирования.
Обновление версии движка для вашей модели голоса
Подсистемы преобразования текста в речь Azure время от времени обновляются для захвата последней языковой модели, определяющей произношение языка. После того, как вы обучили свой голос, вы можете применить свой голос к новой языковой модели, обновив движок до последней версии.
После того, как вы обучили свой голос, вы можете применить свой голос к новой языковой модели, обновив движок до последней версии.
Когда будет доступен новый движок, вам будет предложено обновить модель нейронного голоса.
Перейдите на страницу сведений о модели и следуйте инструкциям на экране, чтобы установить последнюю версию ядра.
В качестве альтернативы выберите Установите последнюю версию ядра позже, чтобы обновить вашу модель до последней версии ядра.
Плата за обновление ядра не взимается. Предыдущие версии по-прежнему сохраняются. Вы можете проверить все версии двигателя для модели из раскрывающегося списка Версия двигателя или удалить одну из них, если она вам больше не нужна.
Обновленная версия автоматически устанавливается по умолчанию. Но вы можете изменить версию по умолчанию, выбрав версию из раскрывающегося списка и выбрав Установить по умолчанию .
Если вы хотите протестировать каждую версию движка вашей модели голоса, вы можете выбрать версию из раскрывающегося списка, а затем выбрать DefaultTests в разделе Testing , чтобы прослушать образцы аудио. Если вы хотите загрузить свои собственные тестовые сценарии для дальнейшего тестирования текущей версии ядра, сначала убедитесь, что версия установлена по умолчанию, а затем выполните описанные выше шаги тестирования.
Обновление движка создаст новую версию модели без дополнительных затрат. После того как вы обновите версию механизма для своей модели голоса, вам необходимо развернуть новую версию, чтобы создать новую конечную точку. Вы можете развернуть только версию по умолчанию.
После создания новой конечной точки вам необходимо передать трафик на новую конечную точку в вашем продукте.
Для получения дополнительной информации узнайте больше о возможностях и ограничениях этой функции, а также о рекомендациях по улучшению качества модели.
Скопируйте вашу голосовую модель в другой проект
Вы можете скопировать вашу голосовую модель в другой проект для того же или другого региона. Например, вы можете скопировать нейронную модель голоса, обученную в одном регионе, в проект для другого региона.
Примечание
Обучение пользовательскому нейронному голосу в настоящее время доступно только в некоторых регионах. Но вы можете легко скопировать нейронную модель голоса из этих регионов в другие регионы. Для получения дополнительной информации см. регионы для Custom Neural Voice.
Чтобы скопировать пользовательскую нейронную модель голоса в другой проект:
На вкладке Модель поезда выберите модель голоса, которую вы хотите скопировать, а затем выберите Копировать в проект .
Выберите регион , речевой ресурс и проект , куда вы хотите скопировать модель.
